Windows Server Failover Cluster WSFC
Overview
In order to build SQL AlwaysOn (SQLAO) Nova a Windows Server Failover Cluster (WSFC) is needed. The WSFC will be built based on the existing Windows Managed OS service. The cluster is built on virtual base, i.e. virtual machine (VM). NOTE: The WSFC is to be considered as embedded service in SQL AO and is not delivered as 'standalone' service.
Short description
- 2 nodes cluster OS Windows 2016 in standard or advanced service level
- Arbitration through Files Share Witness
- Cluster is stretched across two DC (Zol/Wan) in Platinum
- Production NIC (no heartbeat as network traffic is not separated at ESX host level)
- No shared storage at VM level
- No DHCP (fix IP's)
Service specific options
- Service level: advanced default (mirrored storage), option for standard (single site storage).
The chosen service level cannot be changed.
The WSFC will be stretched over two data center in the Platinum (later also in Gold) environment in order to get the highest performance of the ESC infrastructure.
Infrastructure considerations
This chapter describes relevant VM settings which differ from standalone VM offer. This settings are relevant to understand limitations when ordering SQL AO.
VM settings
| Item | Configuration | Description |
|---|---|---|
| HW version | 11 | In order to cover VMware pre-requisites HW Version 11 (and later above) will be used. |
| Name | No customization | The name of the VM cannot be customized. See AD naming convention. |
| Placement | No customization | The placement is fixed in two different data center. Depending on service level placement constraints will be fix implemented. |
Anti-Affinity Rules
Anti-Affinity rules are implemented in the same data center. However cluster node are always spread across data center. At the time being anti-affinity rules cannot be implemented in separate data center. The implementation is planned.
Boot priority
Boot priority depends on the chosen service level:
- standard = normal
- advanced = high
This option can be configured during the ordering. Default option is set on high for every cluster node.
Windows Server Failover Cluster (WSFC)
Windows 2016 allow many different way to configure a failover cluster. Configurations depends on hardware, availability requirements, number of hosts etc. Furthermore there a few constraints and recommendations to follow. The short description in the overview chapter already summarize the configuration of the WSFC for SQLAO nova. In the next chapter some points give a deeper glance in the WSFC setup.
Active directory
SQL AO will be offered ad managed service, i.e. based on the products Managed OS. This means that the placement in the resource domain is mandatory. The CNO (cluster name object) will be registered in the resource domain and follows a name convention. The name convention is applied to the nodes name and to cluster name object (CNO).
- Node 1: AO-DeploymentID-0-C1
- Node 2: AO-DeploymentID-0-C2
- CNO: AO-DeploymentID-0-C0
DNS
The objects mentioned in the chapter above will be registered in the DC integrated DNS as CName. The system will not register automatically themselves in DNS.
Network
The cluster nodes are not configured to use DHCP but will be assigned with fix IP addresses. Connectivity between cluster nodes Windows clustering requires a wide range to be opened between nodes: [https://support.microsoft.com/en-us/help/832017/service-overview-and-network-port-requirements-for-windows].
| Application | Protocol | Ports |
|---|---|---|
| Cluster Service | UDP | 3343 |
| Cluster Service | TCP | 3343 (This port is required during a node join operation.) |
| RPC | TCP | 135 |
| Cluster Administrator | UDP | 137 |
| Randomly allocated high UDP ports | UDP | Random port number between 1024 and 65535 Random port number between 49152 and 65535 |
Configured port matrix
The source and target system are node 1 and node 2 participating in the WSFC based on bidirectional communication.
| Rule | Application Port | Protocol |
|---|---|---|
| Distributed Transaction Coordinator (RPC) | RPC Dynamic Ports 49152 through 65535 | TCP |
| Distributed Transaction Coordinator (RPC-EPMAP) | RPC Endpoint Mapper Ports 49152 through 65535 | TCP |
| Distributed Transaction Coordinator (TCP-In) | Any | TCP |
| Failover Cluster Manager (ICMP4-ER-In) | Any | ICMPv4 |
| Failover Cluster Manager (ICMP6-ER-In) | Any | ICMPv6 |
| Failover Clusters - Named Pipes (NP-In) | 445 | TCP |
| Failover Clusters - Remote Event Log Management (RPC) | RPC Dynamic Ports 49152 through 65535 | TCP |
| Failover Clusters - Remote Registry (RPC) | RPC Dynamic Ports 49152 through 65535 | TCP |
| Failover Clusters - Remote Service Management (RPC) | RPC Dynamic Ports 49152 through 65535 | TCP |
| Failover Clusters - WMI (TCP-In) | Any | TCP |
| Failover Clusters (DCOM server FcSrv TCP-In) | RPC Dynamic Ports 49152 through 65535 | TCP |
| Failover Clusters (DCOM TCP-In) | RPC Dynamic Ports 49152 through 65535 | TCP |
| Failover Clusters (DCOM-RPC-EPMAP-In) | 135 | TCP |
| Failover Clusters (ICMP4-ER-In) | Any | ICMPv4 |
| Failover Clusters (ICMP4-ERQ-In) | Any | ICMPv4 |
| Failover Clusters (ICMP6-ER-In) | Any | ICMPv6 |
| Failover Clusters (ICMP6-ERQ-In) | Any | ICMPv6 |
| Failover Clusters (RPC) | RPC Dynamic Ports 49152 through 65535 | TCP |
| Failover Clusters (TCP-In) | 3343 | TCP |
| Failover Clusters (UDP-In) | 3343 | UDP |
| File and Printer Sharing (SMB-In) | 445 | TCP |
WSFC nodes and arbitration
The WSFC nodes are always placed in two different data center and configured with a "node majority with witness". A file share is configured as witness (FSW) an it is needed for arbitration in failover case only. In order to insure the share availability the hosting VM is configured with advanced service level and it is placed in one of the two data center. The share is placed in one of the two data center. The FSW has to be joined to the same domain as the cluster nodes in order to work. There is one FSW for each domain, i.e. one single FSW system will serve multiple WSFC. The picture below shows the configuration in a simplified way.
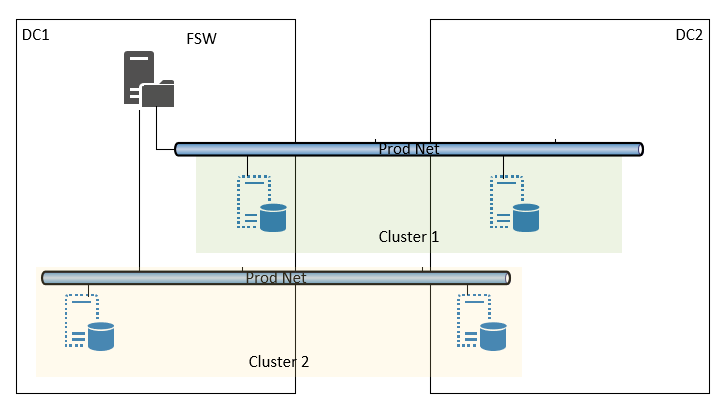
Failure use cases
As it is possible to choose between standard and advanced service it is important to understand the impact of the service level along with the FSW on the system availability. Below you will find four use cases showing the behaviour differentiating between FSW in standard or advanced service level. Failures are differentiate between ESX shortage in the same data center and disaster case, i.e. a whole data center is not longer reachable or at least partially only. In case of disaster the chosen service level affect the service availability along with the placement of the FSW. Please note that recovery time for the FSW can take up to 4 hours.
Note: The use cases below represent the end behaviour once the anti-affinity rules will be full implemented (i.e. across DC's). See chapter above.
Standard maintenance
The picture below shows the behaviour in case of ESX host failure or maintenance.
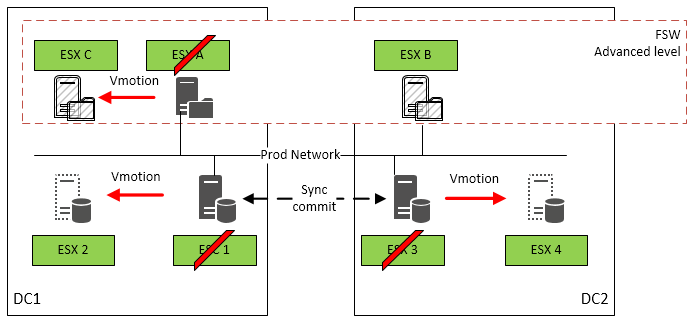
| Case | Description | Service impact |
|---|---|---|
| ESX 1 Maintenance or failure | Cluster node will be moved to ESX 2 | If the node is master a failover to the other node will happen If the node is secondary the synchronization will have a short break not causing down time at all |
| ESX 3 Maintenance or failure | Cluster node will be moved to ESX 4 | If the node is master a failover to the other node will happen If the node is secondary the synchronization will have a short break not causing down time at all |
| ESX A Maintenance or failure | FSW will be moved to ESX C | Cluster is not affected |
Standard service level
In the following picture the server in black show the active placement at the moment of the failure. The dashed FSW shows the target placement after recovery in case of a failure.
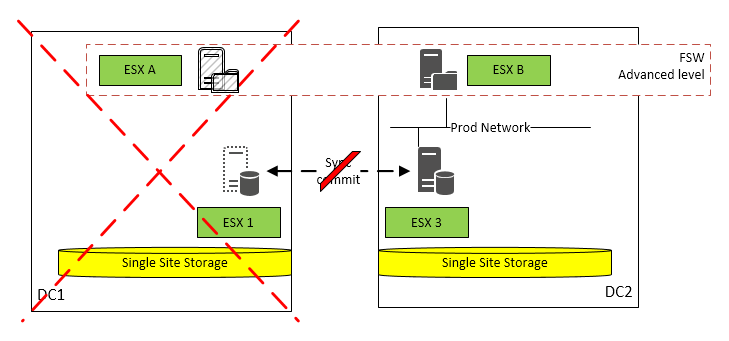
| Case | Description | Service impact |
|---|---|---|
| DC 1 is down | Node on ESX 3 in DC 2 is master FSW is active on ESX B in DC 2 | Node on ESX 1 will go down The cluster maintains node and file majority an will continue operations SQL availability groups remain up and running on ESX 3 High availability is not longer ensured until DC 1 is available again |
| DC 1 is down | Node on ESX 1 in DC 1 is master FSW is active on ESX B in DC 2 | Node on ESX 1 will go down The cluster maintains node and file majority an will continue operations Node on ESX 3 will become master SQL availability groups will failover to node on ESX 3 High availability is not longer ensured until DC 1 is available again |
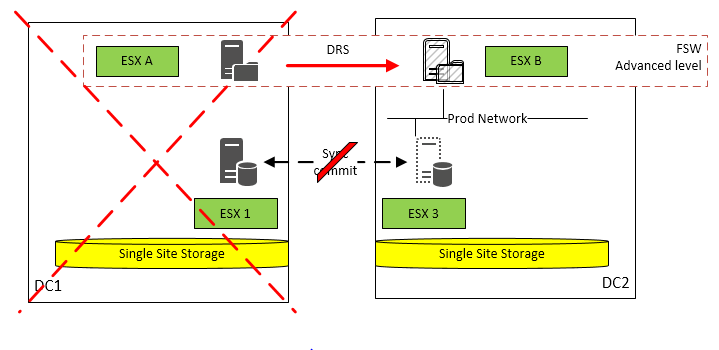
| Case | Description | Service impact |
|---|---|---|
| DC 1 is down | Node on ESX 1 in DC 1 is master FSW is active on ESX A in DC 1 | Node on ESX 1 will go down FSW on ESX A will go down The cluster will loose node and file majority Node on ESX 3 will stay alive, but not reachable through the SQL listener as the cluster service is down FSW will switch to DC 2 on ESX B Cluster becomes operational again without intervention depending on the time elapsed DB's in availabilit< groups on ESX 3 will start a recovery SQL AO will become available again High availability is not longer ensured until operations in DC 1 is available again |
Advanced service level
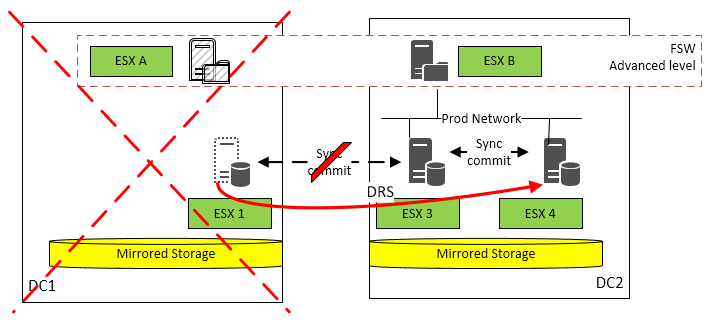
| Case | Description | Service impact |
|---|---|---|
| DC 1 is down | Node on ESX 3 in DC 2 is master FSW is active on ESX B in DC 2 | Node on ESX 1 will go down The cluster maintains node and file majority and will continue operations SQL availability groups remain up and running on ESX 3 High availability is not longer ensured until the node move from ESX 1 to ESX 4 Once the second node is moved to ESX 4 the cluster is operational again SQL AO synchronization has to be recovered automatically if needed |
| DC 1 is down | Node on ESX 1 in DC 1 is master FSW is activ on ESX B in DC 2 | Node on ESX 1 will go down The cluster maintains node and file majority and will continue operations SQL availability groups will failover to node on ESX 3 High availability is not longer ensured until the node move from ESX 1 to ESX 4 Once the second node is moved to ESX 4 the cluster is operational again SQL AO synchronization has to be recovered automatically if needed |
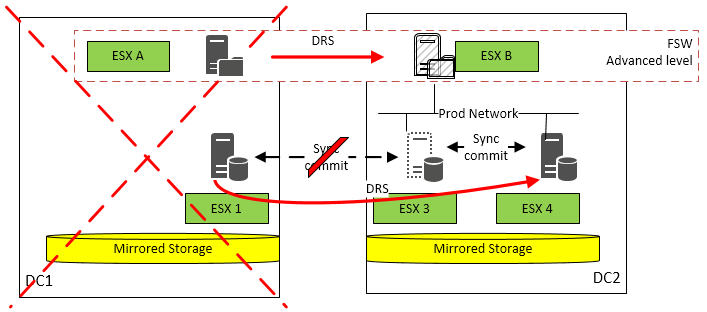
| Case | Description | Service impact |
|---|---|---|
| DC 1 is down | Node on ESX 1 in DC 1 is master FSW is active on ESX A in DC 1 | Node on ESX 1 will go down FSW on ESX A will go down The cluster will loose node and file majority Node on ESX 3 will stay alive, but not reachable through the SQL listener as the cluster service is down FSW will switch to DC 2 on ESX B Node will switch from ESX 1 to ESX 4 Cluster becomes operational again without intervention depending on the time elapsed DB's in availability groups on ESX 3 will start a recovery SQL AO will become available again |
Patching
The patch of the WSFC nodes is enforced to be executed on different scheduling to avoid simultaneous rebooting of nodes partecipating in the same cluster.
Summary
The table below summarize the differences to the Managed OS product.
| Configuration Level | Configuration Item | Type | Description |
|---|---|---|---|
| Service | Level | No basic service level | Only standard and advanced level are allowed. |
| Sizing | Reconfiguration | CPU/RAM/Disks | Maintenance mode is not allowed. VM sizing cannot be modified after provisioning. |
| OS | Version | Windows 2016 only | Managed OS Windows 2016. |
| OS | Patching | Different schedules | The WSFC nodes cannot be patched on the same schedule. |
| OS | Backup | Snapshot schedules | The WSFC node snapshot has to be executed at different schedules. |
| OS | Local Firewall | Enabled rules | Windows Firewall Remote Management (RPC) Windows Firewall Remote Management (RPC-EPMAP) Windows Management Instrumentation (WMI-In) File and Printer Sharing (SMB-In) File and Printer Sharing (Echo Request - ICMPv4-In) File and Printer Sharing (Echo Request - ICMPv6-In) |
| Network | DHCP | Fix IP | DHCP is not allowed. |